
Nvidia are o poziție extrem de puternică pe piața acceleratoarelor de inteligență artificială, datorită acceleratoarelor sale bazate pe GPU Ampere și Hopper, care oferă performanțe extraordinare și sunt extrem de populare, ceea ce face din această companie dominatorul al acestui segment. S-a vorbit anterior despre faptul că în curând vor sosi acceleratoarele AI bazate pe arhitectura Blackwell, care ar putea oferi performanțe extraordinare, iar acestea au fost prezentate la GTC 2024 de ieri, deși doar parțial, deoarece producătorul nu a dezvăluit totul în prezentarea sa oficială și au rămas multe întrebări la care trebuie să se răspundă.

Nu este un secret pentru nimeni că arhitectura Blackwell este construită în jurul a două produse majore, unul este GPU B200 și celălalt este Superchip GB200, care are două GPU B200 și un procesor Nvidia Grace bazat pe ARM. În comparație cu actualul Hopper H100, care se află în vârful de gamă al ofertei Nvidia pe piața AI, B200 poate fi de până la cinci ori mai rapid pentru sarcinile de deducere, ceea ce nu este o îmbunătățire mică. În același timp, cu GPU-ul dispune de o memorie de patru ori mai mare, ceea ce ar trebui să fie o veste binevenită pentru parteneri.
GPU-ul B200 este de fapt alcătuit din două chipset-uri, care sunt la rândul lor alcătuite din 104 miliarde tranzistori fiecare, și sunt în prezent cele mai mari din clasa lor. Cele două chipseturi ale GPU B200 sunt fabricate cu ajutorul tehnologiei de fabricație de ultimă generație și de cea mai înaltă performanță din clasa 4N de la TSMC, cunoscută sub numele de 4NP. GPU-ul este construit cu un total de 208 miliarde de tranzistori și cu o interconectare unică între cele două chipseturi, care asigură o lățime de bandă ultra-înaltă de 10 TB/s. Datorită acestuia, comunicarea dintre chipset-uri este suficient de rapidă și cu o latență suficient de scăzută, adică se realizează coerența cache-ului, adică GPU-urile pot accesa spațiul de memorie al celuilalt la aceeași viteză ca și cum ar fi al lor, cu o conexiune directă.

Subsistemul de memorie pentru ambele chipset-uri este un subsistem de memorie pe 4096 de biți, care este conectat la 96 GB de memorie on-board de tip HBM3E, disponibilă sub forma a patru sandvișuri de cipuri de memorie de 24 GB, astfel că în total cipul B200 poate implementa un total de 192 GB de memorie on-board. Lățimea de bandă a memoriei nu a fost nici ea uitată, aceasta fiind de 8 TB/s, nu cu mult mai mică decât interconectarea individuală care asigură legătura între chipset-uri. Bineînțeles, este prezent și suportul NVLink, care permite GPU-ului să se conecteze la server și la un alt cip B200, cu o lățime de bandă de 1,8 TB/s, ceea ce este deasemenea, masiv.

În plus, compania a introdus și Superchip-ul GB200, care conține acum un total de două GPU GB200, pentru un total de patru chipset-uri cu un total de 384 GB de memorie la bord. Construite dintr-un total de 416 miliarde de tranzistori, GPU-urile comunică, prin NVLink, iar la bord se află și un Grace Superchip bazat pe ARM, care ar putea fi generația anterioară GH200 Grace Hopper Superchip, deoarece produsul nu a fost lăudat de către omul de frunte al Nvidia, deci este puțin probabil să fie o noutate. Grace-Hopper Superchip este preferabil unui procesor pentru servere AMD EPYC sau Xeon Scalable din seria x86-64, deoarece NVLink oferă o conexiune cu o lățime de bandă de date mai mare între componente, iar arhitectura specială face ca acest cip să fie mai potrivit pentru fluxurile de lucru AI.
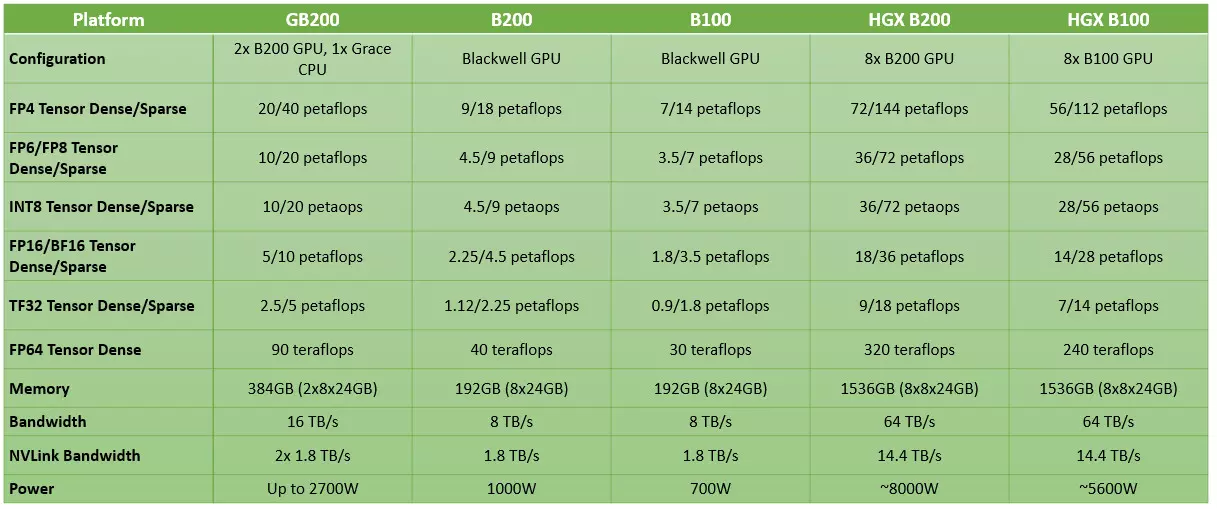
Acest lucru ne aduce la performanța GPU-urilor individuale B200 și a soluției GB200. Din nefericire, șeful Nvidia nu a dezvăluit exact cum este construit fiecare GPU, astfel că nu se cunosc parametrii exacți ai matricelor SM, nucleelor CUDA, nucleelor Tensor și ai cache-urilor, dar ne putem aștepta la o putere de calcul uriașă. Se pare că fiecare cip B200 individual este capabil să atingă o performanță de calcul de 20 PFLOP/s în timpul fluxurilor de lucru de deducere, ceea ce se traduce în 20.000 TFLOP/s. Pentru GB200, această valoare ar putea ajunge la 40 PFLOP/s dacă se utilizează performanța de calcul Tensor FP4. Performanța de calcul FP64 este, de asemenea, impresionantă, cu o valoare de 90 TFLOP/s, de trei ori mai mare decât cea a GH200 bazat pe Hopper.
Desigur, merită subliniat faptul că performanța de 20 PFLOP/s a B200, folosind formatul numeric FP4, este puțin înșelătoare în ceea ce privește accelerarea. Dacă ne uităm la nivelul FP8, unde performanța este la jumătate față de FP4, diferența de performanță dintre B200 și H100 nu este de cinci ori, ci de două ori și jumătate (10 PFLOP/s față de 4 PFLOP/s), astfel încât este realist să comparăm mere cu mere, nu performanța FP4 cu FP8.
Noile dezvoltări de la Nvidia sunt așteptate să fie lansate în cursul acestui an.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}