În cadrul prezentării sale de la Computex 2024, Intel a dezvăluit seria de procesoare mobile Lunar Lake, care va înlocui Meteor Lake mult mai slabe. Noile procesoare vor fi disponibile doar în formă mobilă și vor fi disponibile pe desktop doar la bordul unor sisteme compacte, cum ar fi produsele din seria NUC și alte soluții de dimensiuni similare.

Oficialii producătorului au dezvăluit ceea ce trebuie să știi despre chipset-ul Lunar Lake, în ceea ce privește arhitectura sa și creșterile aproximative de viteză pe care le-ar putea aduce în anumite domenii, comparativ cu Meteor Lake. Din păcate, încă nu au fost anunțate modele specifice și nici nu au oferit detalii despre unde se situează performanțele lui Lunar Lake în comparație cu procesoarele mobile rivale, dar acest aspect va fi abordat pe măsură ce se apropie data planificată a lansării.
Schema generală a arhitecturii cipului Lunar Lake

La fel ca în cazul seriei Meteor Lake, aceste unități SoC vor fi alcătuite tot din unități segmente de dreptunghiuri aéezate eficient (Tile design), dar arhitectura acestora s-a schimbat. Compute Tile conține nucleele procesorului, Graphics Tile găzduiește iGPU și un Platform Controller Tile pentru a găzdui componentele pentru secțiunea I/O. Interesant este faptul că nici una dintre aceste plăci nu este fabricată de Intel, de data aceasta toate au fost externalizate către TSMC: Compute Tile este fabricat cu ajutorul wafer-ului TSMC de 3nm clasa N3B, în timp ce Platform Controller Tile este creat cu ajutorul tehnologiei de fabricație N6 de 6nm al TSMC.
Aceste plăci sunt așezate pe o placă numită Base Tile, care asigură comunicarea între ele folosind Foveros. Base Tile este construită la fabrica Intel, folosind o tehnologie pe 22 nm. Base Tile este așezată direct pe carcasă, iar peste ea a fost adăugată o nouă componentă, memoria RAM.

Am văzut deja acest design pe un exemplu de test al seriei Meteor Lake, cipul Meteor Lake-MX, dar conceptul este abia acum gata să fie pus la bordul unui SoC comercial. Fiind vorba de o soluție mobilă, foliosește module LPDDR5X, care poate funcționa la 8500 MHz. Memoria de bord poate fi de până la 32 GB, și este alcătuită din maxim două cipuri, astfel încât poate profita de suportul de memorie pe 2 x 64 de biți, care este de fapt 4 canale de memorie pe 16 biți.
Noul design este un design cu 40% mai compact pentru subsistemul de memorie decât ar fi posibil cu modulele de memorie So-DIMM, sau cu noul modul de memorie LPCAMM2. Cu toate acestea, dezavantajul este că în timp ce acestea din urmă permit extinderea memoriei on-board, acest lucru nu este posibil cu memoria on-board integrată în procesor, iar montarea ulterioară a cipurilor de memorie va fi mai dificilă sau imposibilă, chiar și pentru un tehnician calificat.
Schimbarea arhitecturii CPU, pierderea suportului Hyper-Threading

În cazul Lunar Lake, procesorul poate avea maximum 8 nuclee și 8 fire de execuție, deoarece suportul Hyper-Threading nu mai este disponibil pentru partea P-Core. Cele 8 nuclee ale procesorului sunt alcătuite din patru nuclee Lion Cove și patru nuclee Skymont, primele pentru P-Core, iar cele din urmă pentru E-Core. O schimbare foarte importantă este că nu se mai utilizează ca până acum memoria cache partajată de al treilea nivel: în locul unei singure memorii cache partajate de al treilea nivel, diviziile E-Core și P-Core au propriile memorii cache, iar comunicarea între ele se face prin intermediul interconectării interne cu lățime de bandă mare, fără interconectarea clasică bazată pe ringbus. Cele patru nuclee P-Core au acces la maximum 12 MB de L3 Cache în total, în timp ce E-Core nu are L3 Cache. L2 este împărțit între cele patru nuclee de procesare Skymont, cu o capacitate totală de 4 MB.
Nucleele procesorului Lion Cove, adică P-Core
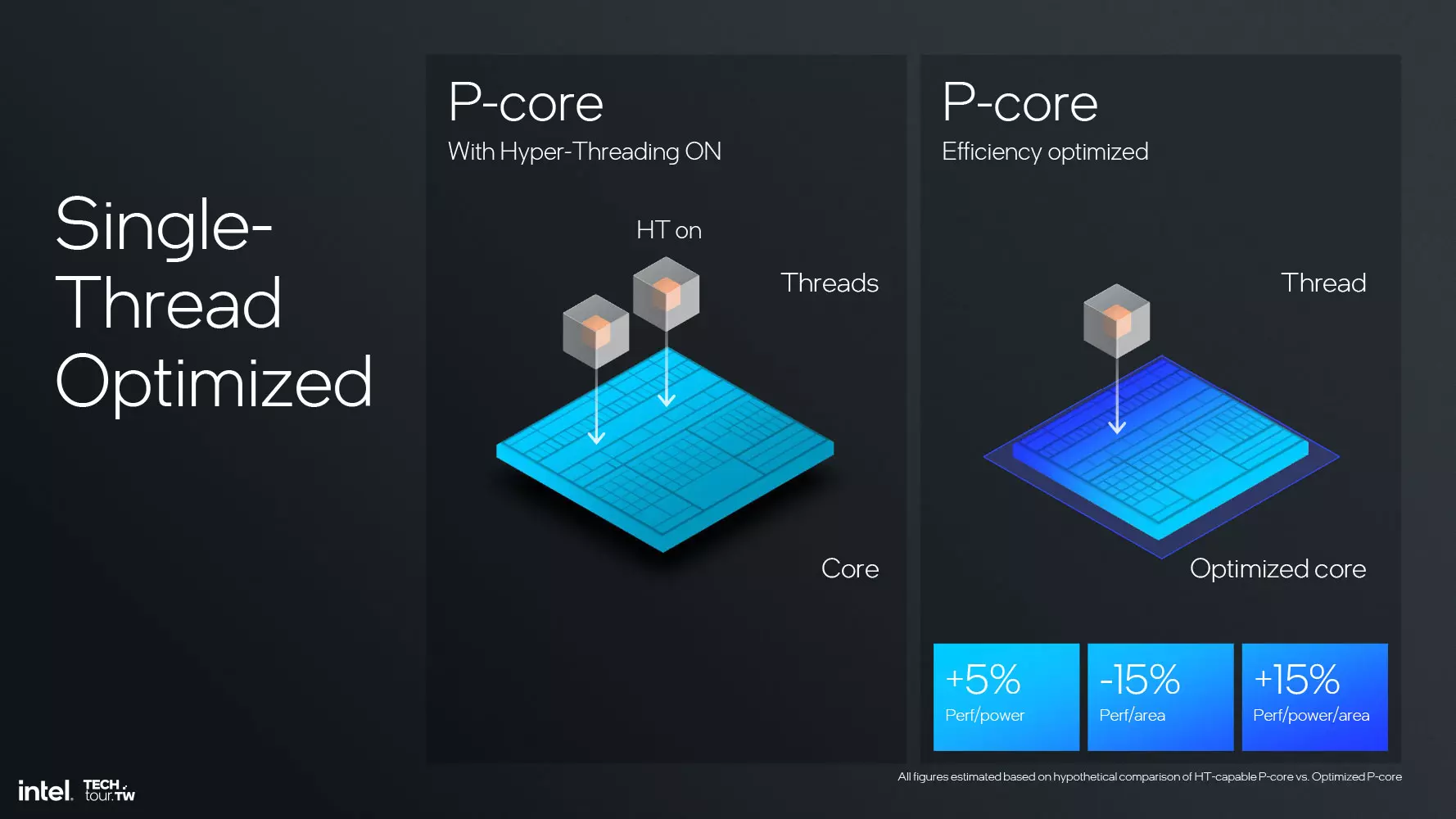
Intel a renunțat la suportul Hyper-Threading pentru matricea cu maximum 4 nuclee, deoarece este din ce în ce mai puțin necesar pe procesoarele hibride, iar utilizarea Hyper-Threading nu a fost foarte eficientă până acum, deoarece a fost folosită în mare parte doar atunci când secțiunile E-Core și P-Core sunt complet încărcate, ceea ce nu reprezintă o performanță optimă, cel puțin conform producătorului.
Odată cu eliminarea suportului pentru Hyper-Threading, componentele hardware care controlează al doilea fir pot fi eliminate, iar spațiul eliberat poate fi folosit pentru a îmbunătăți raportul performanță/watt prin creșterea capacității celorlalte componente, iar viteza ceasului poate fi crescută prin puterea eliberată. Echipa Intel a calculat că, prin eliminarea Hyper-Threading din nucleele procesorului Lion Cove, raportul performanță/watt în zona respectivă s-a îmbunătățit cu 15%, raportul performanță/consum s-a îmbunătățit cu 5% și s-a economisit 15% din spațiu.
Spațiul astfel eliberat a fost folosit pentru reproiectarea nucleelor. De exemplu Front-end-ul are blocuri de estimare a ramificațiilor este de 8 ori mai mari, dar are și o unitate Fetch mai largă, o lățime de bandă de decodare mai mare și o capacitate mai mare a cache-ului micro-op. O schimbare foarte interesantă este introducerea unei noi categorii numite "Nano-Ops", care reprezintă o defalcare suplimentară a operațiilor micro-op care pot fi efectuate în paralel în mod eficient datorită similitudinilor lor, crescând astfel performanța.
În motorul Out Of Order Engine, domeniile Int și Vec au fost divizate pentru a permite operarea unor redenumiri și planificatoare independente, economisind astfel energie în timpul fluxurilor de lucru specifice domeniului. Membrii celor două domenii au acces independent la coada de așteptare a microoperațiunilor cu planificatoare independente, ceea ce contribuie în mod cert la îmbunătățirea performanței. Motorul Out of Order Engine a fost îmbunătățit în mai multe domenii, numărul de porturi de execuție a crescut de la 12 la 18, iar capacitatea ferestrei de instrucțiuni profunde a crescut de la 512 la 576.
Retirement Queue a fost mărită cu 50%, iar lățimea de alocare/redenumire a fost mărită de la 6 la 8. O altă modificare importantă este că numărul de unități ALU pentru numere întregi a fost mărit de la 5 la 6, există acum 3 unități Jump Unit și 3 unități Shift Unit la bord în loc de 2, iar proiectul are acum 3 unități Mul Unit în loc de 1. Alte modificări includ extinderea motorului de execuție vectorială, care poate folosi acum 4 SIMD ALU în loc de 3. Există acum două FMA-uri cu o latență de 4 cicluri, iar secțiunea FP Divider a fost mărită de la 1 la 2, cu latență redusă și performanță crescută.
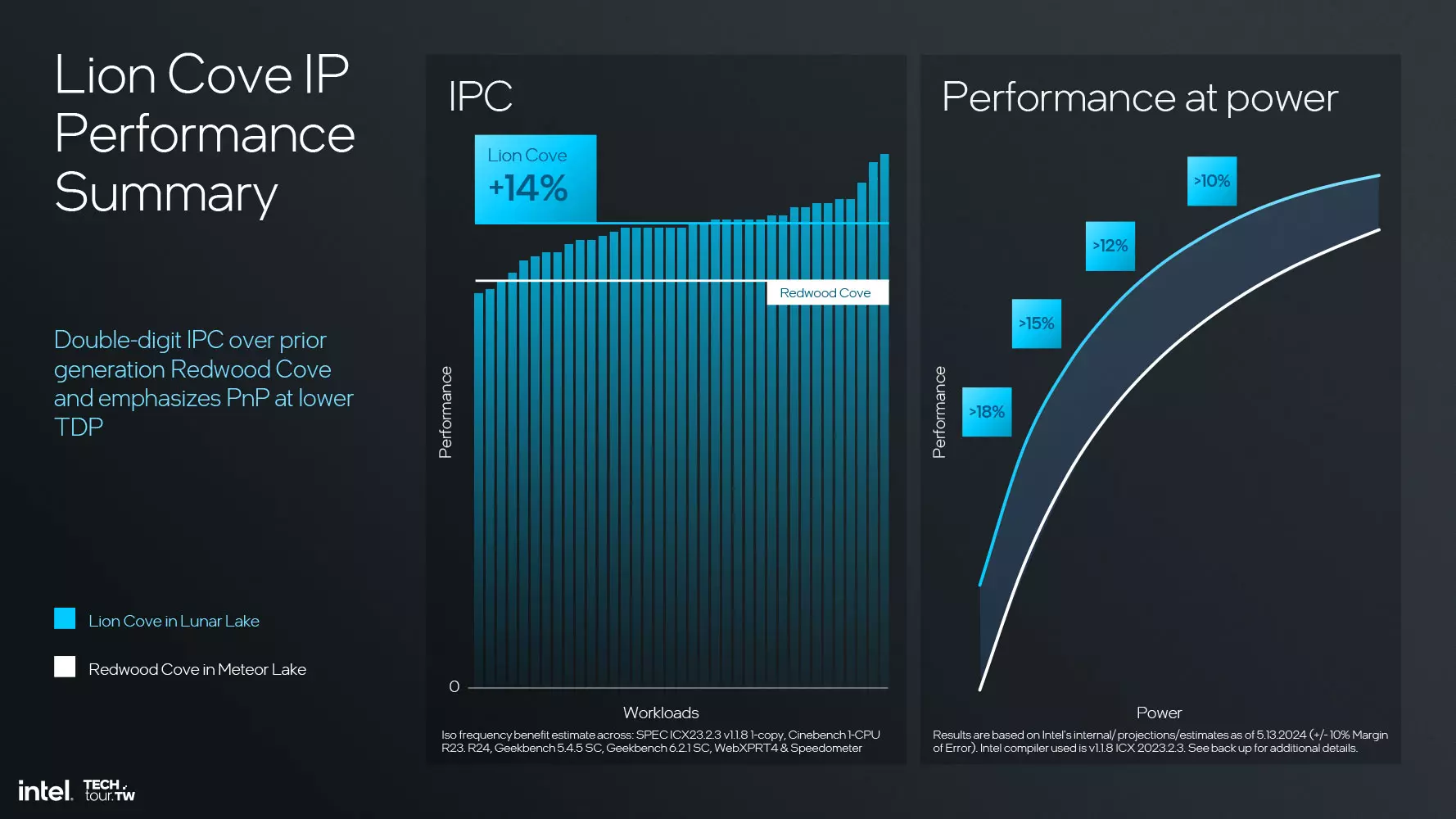
Subsistemul Load-Store a suferit și el unele modificări, DTLB lucrând acum cu 128 de carduri în loc de 96, iar STA AGU a trecut de la 2 la 3. Potrivit Intel, nucleele de procesare Lion Cove de la bordul Lunar Lake pot efectua cu 14% mai multe operații pe ciclu de ceas decât nucleele de procesare Redwood Cove utilizate în procesoarele Meteor Lake, dar pot atinge și o creștere de până la 18% în unele cazuri.

Subsistemul de memorie a fost și el modificat, nucleele procesorului Lion Cove trecând de la precedentul L1D Cache la L0D Cache, care poate fi conectat la 192 KB L1 C-Cache. Capacitatea L2 Cache pentru modelele Lunar Lake va fi de 2,5 MB per nucleu, în timp ce procesoarele Arrow Lake, care folosesc nuclee de procesor Lion Cove, vor avea 3 MB de L2 Cache per nucleu. După cum s-a menționat mai sus, cele patru nuclee P-Core vor avea acum propriul lor cache partajat de al treilea nivel, care nu va fi partajat cu E-Core, cu o capacitate de 12 MB la implementarea maximă.
Secțiunea E-Core va fi combinată

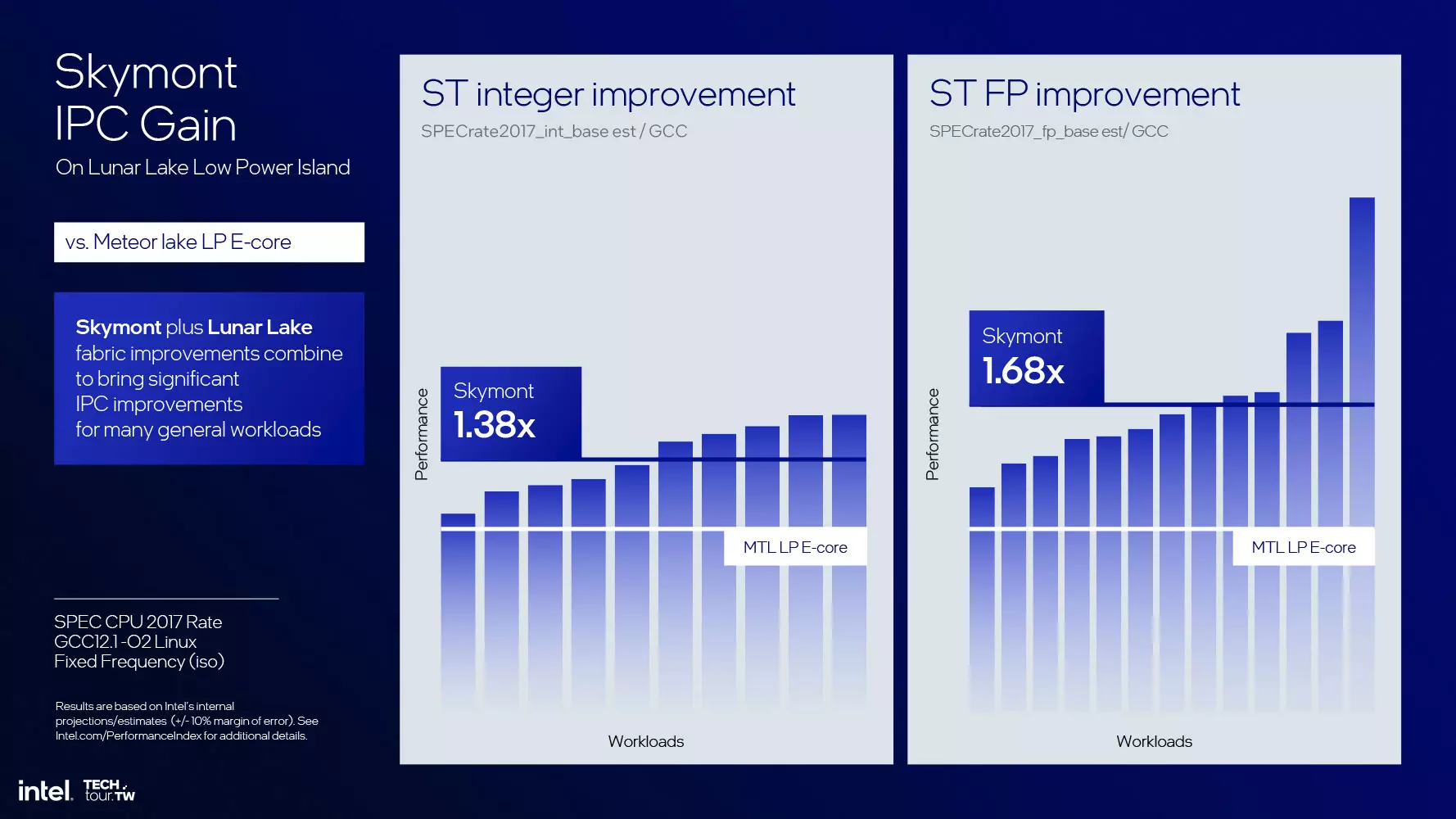
Lunar Lake folosește nuclee de procesare Skymont în locul nucleelor Crestmont anterioare, despre care Intel susține că vor oferi o creștere de 68% a IPC, o îmbunătățire semnificativă. Trebuie adăugat că această comparație se referă la secțiunea E-Core de pe Tile SoC Meteor Lake, ceea ce poate fi corect, deoarece cele două nuclee LP Crestmont nu sunt conectate la ringbus-ul utilizat de secțiunile P-Core și E-Core, și nici nucleele Skymont nu sunt conectate la ele. Îmbunătățirea eficienței energetice (raportul putere/watt) a fost îmbunătățită cu 300%, în timp ce, dacă luăm în considerare același consum de energie, obținem o performanță de 2,9 ori mai bună. Atunci când nucleele Skymont de pe cipul Lunar Lake sunt împinse la limite, se poate obține o performanță de până la patru ori mai mare decât cea a nucleelor Crestmont LP, ceea ce reprezintă o îmbunătățire semnificativă.
În esență, din cauza celor de mai sus, Intel s-a gândit să reproiecteze dispunerea nucleelor procesorului, renunțând la suportul Hyper-Threading în divizia P-Core și folosind spațiul eliberat pentru a consolida diviziile E-Core și P-Core. Un E-Core semnificativ mai puternic și un P-Core întărit pot înlocui suportul Hyper-Threading, și pot oferi creșteri semnificative de viteză fără acesta.
Modificările aduse unității de predicție Fetch și Branch Prediction Unit, unde pot fi utilizate în paralel până la 96 de instrucțiuni în același timp, iar Branch Estimation poate privi înainte cu 128 de octeți atunci când caută posibile ramificații, îmbunătățind performanța. Front-end-ul s-a schimbat și aici, unitatea de decodare cu operând într-un sistem 9-wide față de 6, iar suportul Nano-Core menționat pentru nucleele procesorului Lion Cove, care permite ca microoperații similare să fie împerecheate și efectuate în paralel.
O altă schimbare semnificativă este că capacitatea Micro-Op Cache a fost mărită la 96 de intrări în loc de 64, cât era anterior. Arhitectura motorului Out of Order Engine s-a schimbat de pe 6 la 8-wide, iar Retire Queue are acum o arhitectură 16-wide în loc de 8, dublând performanța. Caracteristica Depedency Breaking reduce latența. Fereastra Out of Order a fost lărgită semnificativ, de la 256 la 416 intrări, registrele fizice au fost mărite, stația de rezervare Int, Mem și Vector Reservation Station a fost mărită, iar cache-ul Load și Store a devenit mai larg.
Motorul de execuție are acum 26 de porturi Dispatch, astfel încât există 8 porturi Integer Alu și 3 porturi Jump port, fiind posibil executarea a 3 încărcări pe ciclu, o îmbunătățire de 50%. Motorul vectorial a fost modificat și ea, cu patru FPU pe 128 de biți, dublând GFLOp/s. Latențele FMUL, FMA și FADD au fost reduse, iar rotunjirea în virgulă mobilă va rula cu accelerare hardware nativă. Performanța AI a crescut datorită unităților de procesare suplimentare.

În cazul E-Core, cele patru nuclee de procesare pot accesa un total de 4 MB de cache de al doilea nivel, dar în acest caz lățimea de bandă a cache-ului L2 a crescut de la 64 B la 128 B pe ciclu de ceas, iar lățimea de bandă L1-L1 între nuclee a crescut și ea, ceea ce a dus la o comunicare mai rapidă. Pe baza testelor interne, IPC a crescut cu 38%, iar performanța în virgulă mobilă este cu 68% mai mare decât cea a nucleelor Crestmont LP, care în modelele Meteor Lake au fost utilizate pe placa SoC Tile în mod izolat față de celelalte nuclee.
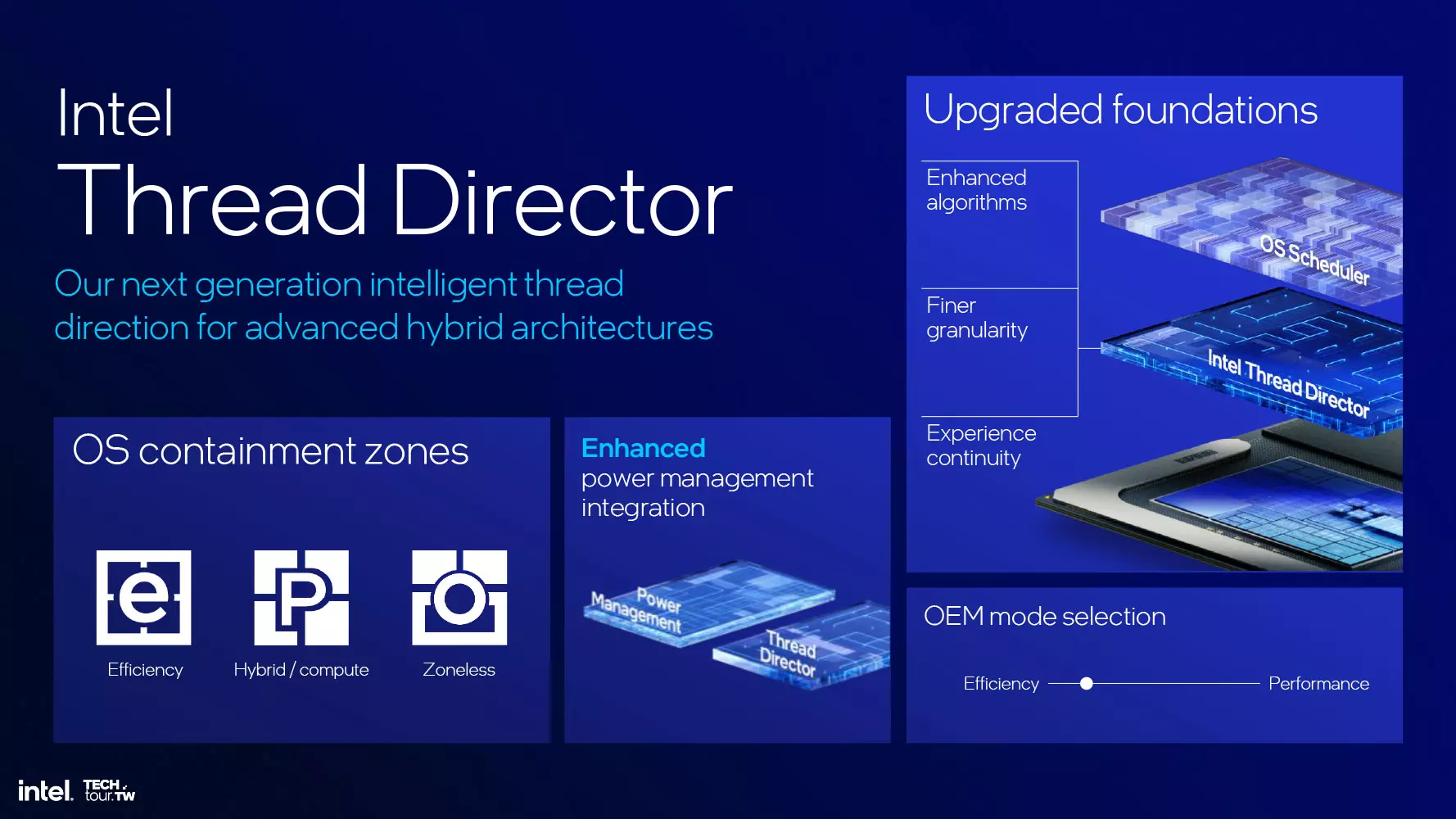
Thread Director a fost îmbunătățit

Această componentă avansată asigură direcționarea diferitelor sarcini de lucru către cel mai adecvat fir de procesor sau nuclee de fire pentru o performanță optimă. Noua versiune distribuie sarcinile în mod mai inteligent, îmbunătățind în același timp interacțiunea cu sistemul de operare și cu sistemul OEM, permițând un control mai precis și mai eficient al planificării.
De asemenea, au fost îmbunătățite capacitățile de eficiență energetică, ceea ce poate crește durata de viață a bateriei. În cadrul planificării dinamice, E-Core este rezervat mai întâi, în cazul în care natura modelului de încărcare este adecvată, iar apoi sunt încărcate celelalte nuclee din secțiunea E-Core. Dacă este necesar, se dă drumul și nucleelor P-Core, dacă natura sarcinii o impune. Acesta este modul de funcționare implicit.

Cu noul Thread Director, va fi posibil să se precizeze ce software trebuie să ruleze pe ce tipuri de nucleu, restricționându-l numai la E-Core sau numai la P-Core, dar permițând, de asemenea, ca aplicația să ruleze în mod "fără zone", adică fără a fi restricționată la niciunul dintre departamente.
Debutează arhitectura Xe2, vlaca video integrată este semnificativ mai rapid

Unitățile SoC Lunar Lake nu aduc doar îmbunătățiri ale nucleelor de procesor, ci și îmbunătățiri ale iGPU, și chiar unele destul de semnificative, deoarece Intel susține că noul iGPU construit în jurul arhitecturii Xe2 va oferi performanțe cu 50% mai bune în jocuri, comparativ cu iGPU-ul bazat pe Xe-LPG de la bordul Meteor Lake. Noul iGPU se va baza în continuare pe nuclee Xe, dar aici va acționa a doua generație de nuclee Xe. În acest design, există un total de 8 motoare vectoriale pe 512 biți, 8 motoare matematice matriciale XMX pe 2048 de biți, suport pentru operații atomice pe 64 de biți și un L1 Cache partajat îngrășat de 192 KB.

Cea mai mare noutate față de designul iGPU din seria Alchemist este că motorul XMX este prezent. Cu 8 nuclee Xe2, iGPU conține 1024 de shadere, care împreună cu unitățile XMX, pot oferi un total de 67 de TOP de performanță pentru sarcini de lucru de tip AI, în timp ce sarcinile de ray-tracing sunt gestionate de 8 unități RT.

Urmează motorul media, care oferă accelerare hardware pentru codificarea și decodificarea conținutului AV1 și introduce suport pentru accelerare hardware pentru formatului VVC, acoperind în esență codecurile H.266. Rezultă o dimensiune a fișierului cu doar 10% mai mică decât AV1 la aceeași calitate, dar care suportă video la 360 de grade, vizualizare panoramică și rezoluție adaptivă.
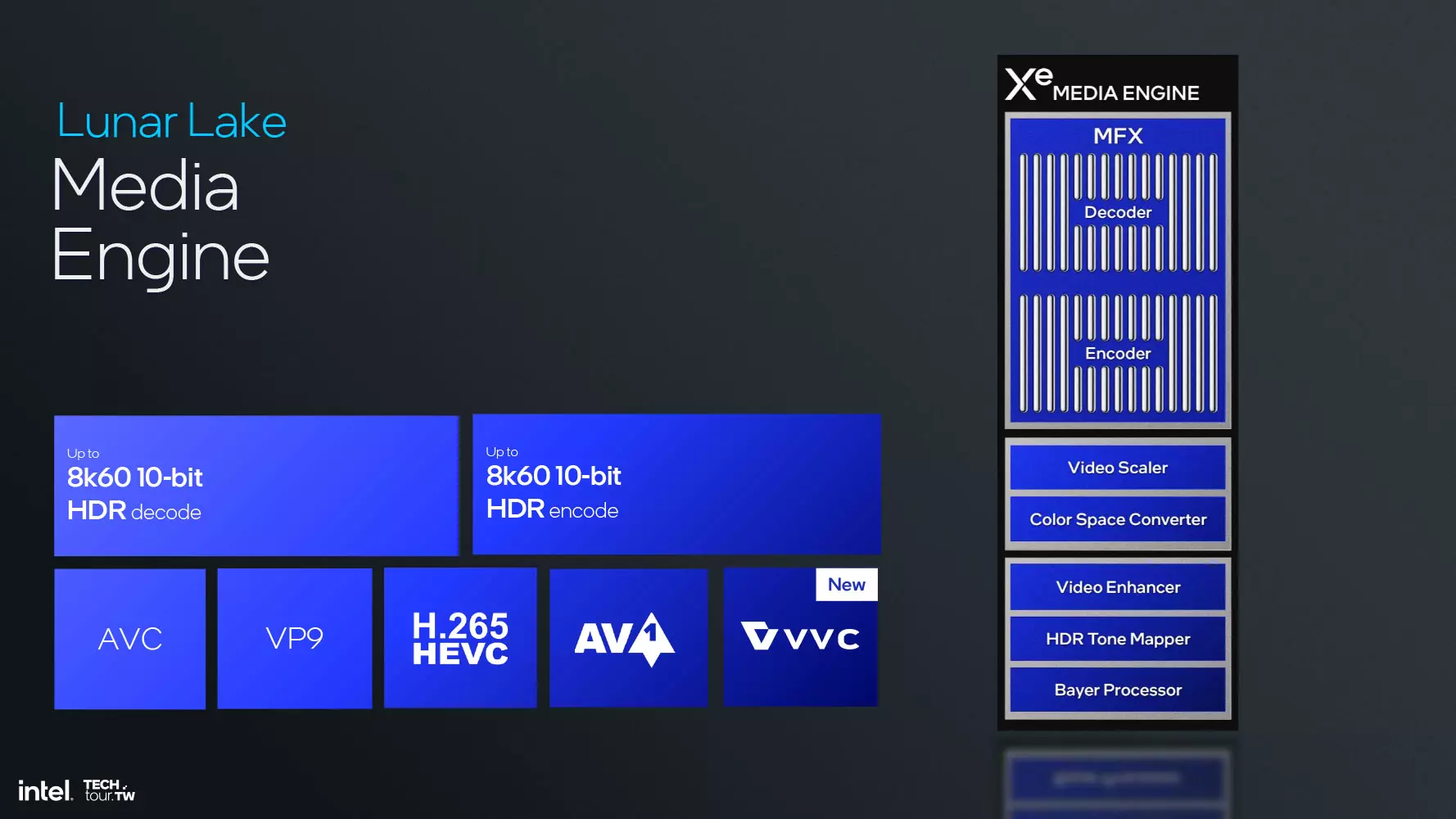
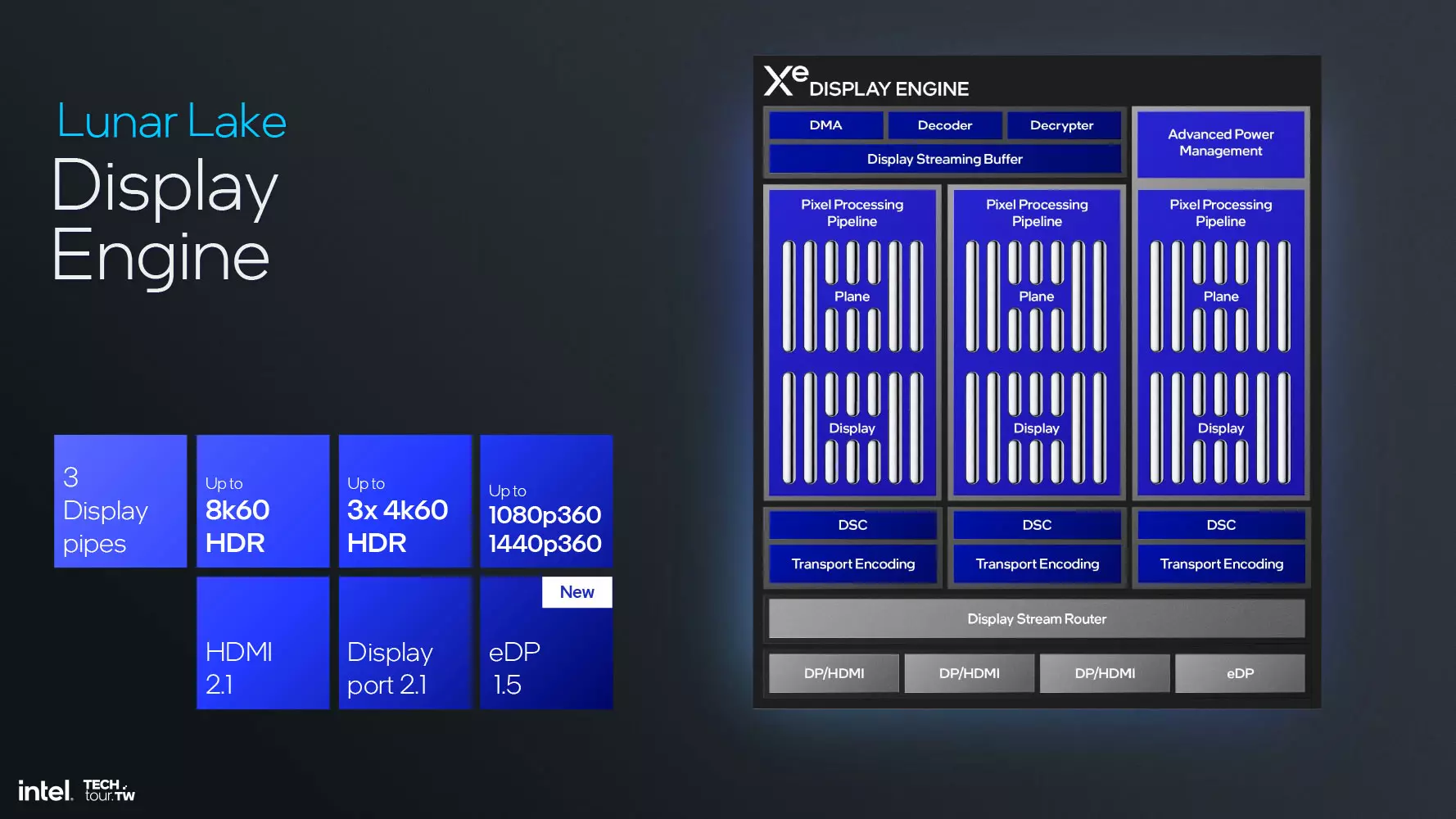
Motorul de afișare vine cu suport pentru eDisplayPort 1.5, dar suportă și HDMI 2.1 și DisplayPort 2.1. Autoactualizarea panoului, reîmprospătarea selectivă și Adaptive Sync sunt toate disponibile pentru eDP, precum și Panel Replay. Împreună, acestea contribuie la reducerea consumului de energie al notebook-ului prin actualizarea doar a părților din afișaj în care au fost efectuate modificări, adică ceea ce este efectiv necesar, nu a întregului afișaj. Bineînțeles, acestea nu sunt bune doar pentru eficiența energetică, ci și pentru o experiență vizuală mai bună, deoarece pot reduce latența afișajului, cresc precizia sincronizării și asigură o vizualizare fluidă.
Îmbunătățiri importante la NPU

Având în vedere că AI-ul este la ordinea zilei, iar Microsoft necesită un NPU puternic în fiecare unitate SoC pentru a se încadra în categoria PC-urilor Copilot+, echipa Intel nu a avut de ales decât să crească semnificativ performanța NPU-ului. Cea de-a patra generație de NPU este acum capabilă de 48 de TOP în cadrul sarcinilor INT8, o creștere semnificativă a vitezei față de soluția de generația a treia de la bordul unităților Meteor Lake. Aceasta din urmă a fost capabilă să atingă doar 12 TOP, o îmbunătățire de patru ori mai mare, ceea ce este suficient pentru a plasa Lunar Lake în categoria PC-urilor Copilot+.
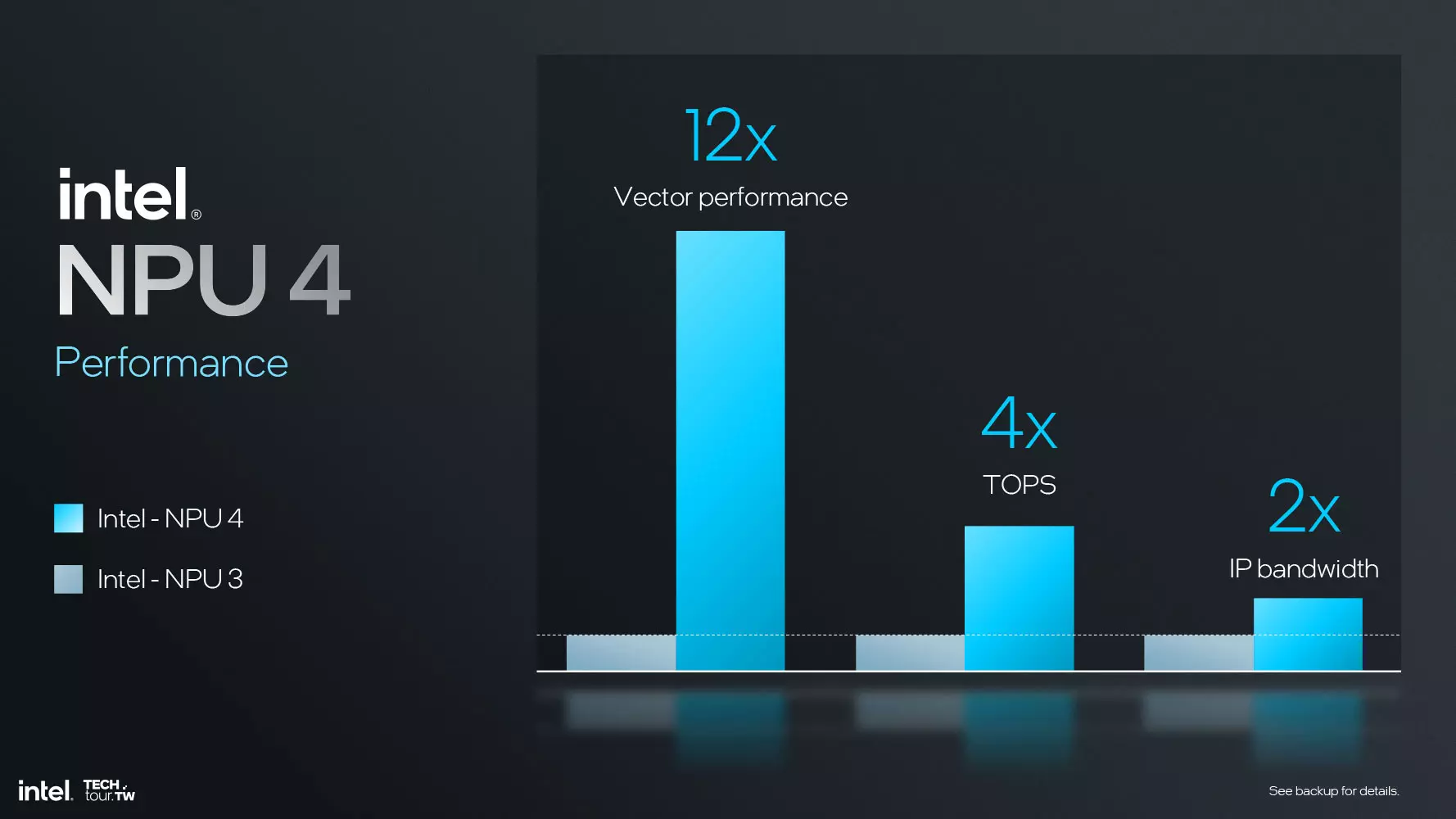
Această accelerare se datorează parțial îmbunătățirilor semnificative ale arhitecturii NPU, inclusiv creșterii numărului Neural Compute Engines de la 2 la 6, dar și unui pas mai mare în ceea ce privește eficiența energetică. Pentru a crește performanța, a fost necesară creșterea lățimii de bandă DMA și a capacității L2 Cache, precum și a vitezei de ceas. Eficiența energetică a fost dublată datorită noilor tehnologii de fabricație și altor modificări din fundal.
Capacitățile avansate de conversie a datelor sunt și ele disponibile pentru noua matrice MAC, astfel încât tipurile de date pot fi convertite în timp real, on-chip, diferite operații pot fi îmbinate și structura datelor de ieșire poate fi modificată, optimizând astfel fluxul de date și reducând latența.
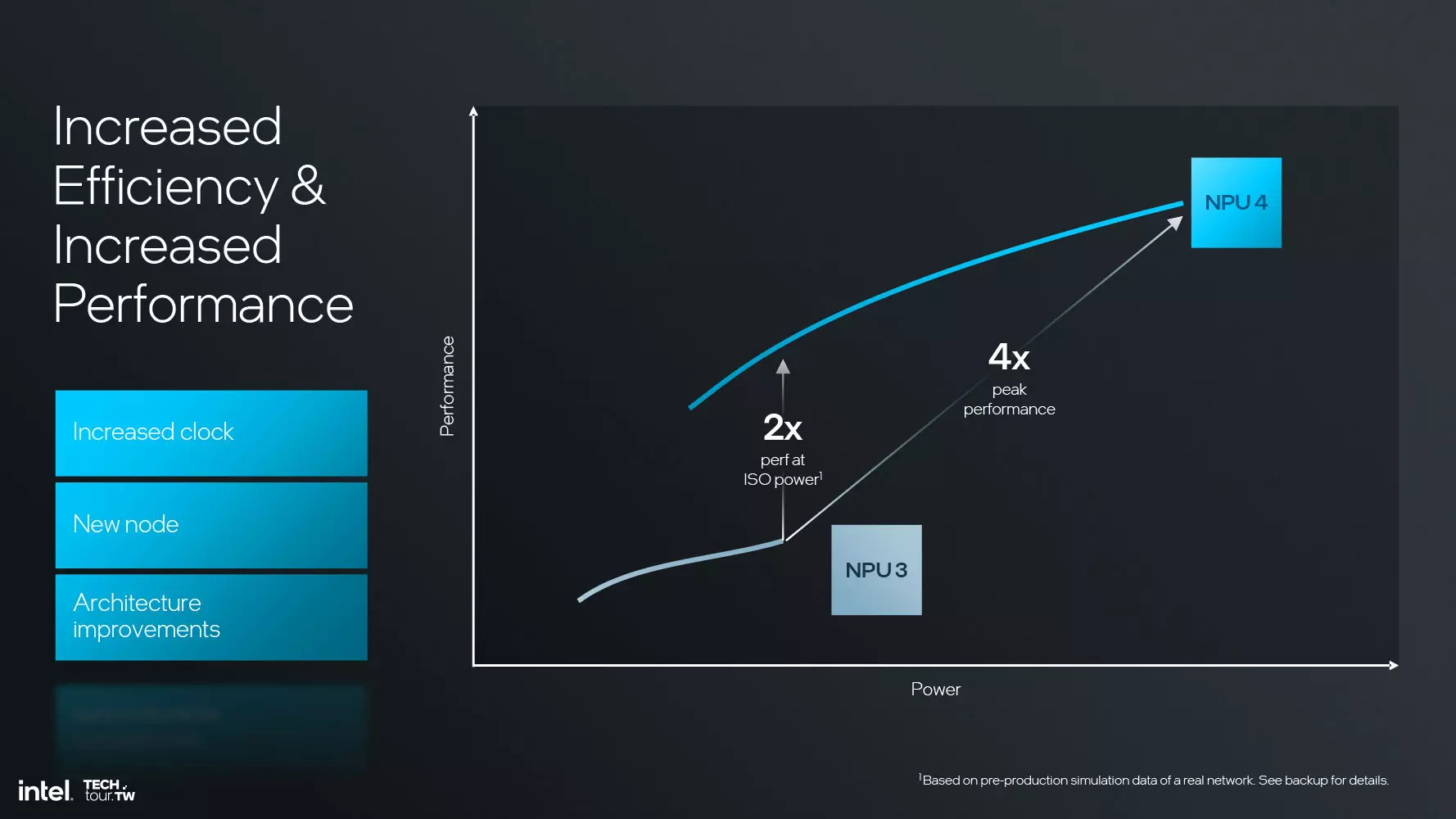
În general, performanța vectorială brută a NPU 4 este de 12 ori mai mare decât cea a NPU 3, performanța AI TOPS este de patru ori mai mare, iar lățimea de bandă între NPU și interconectare este dublă. Ca o notă secundară interesantă, Intel susține că performanța AI va fi de maxim 120 TOPS odată cu sosirea Lunar Lake, incluzând performanța NPU, iGPU și CPU.
Platform Controller Tile

Plăcuța care controlează secțiunea I/O, creată cu tehnologia de 6 nm al TSMC, prezintă o serie de inovații. Cipul include un controler Wi-Fi 7, care permite o lățime de bandă wireless totală de până la 5,8 Gbps, dar oferă și suport Bluetooth 5.4.
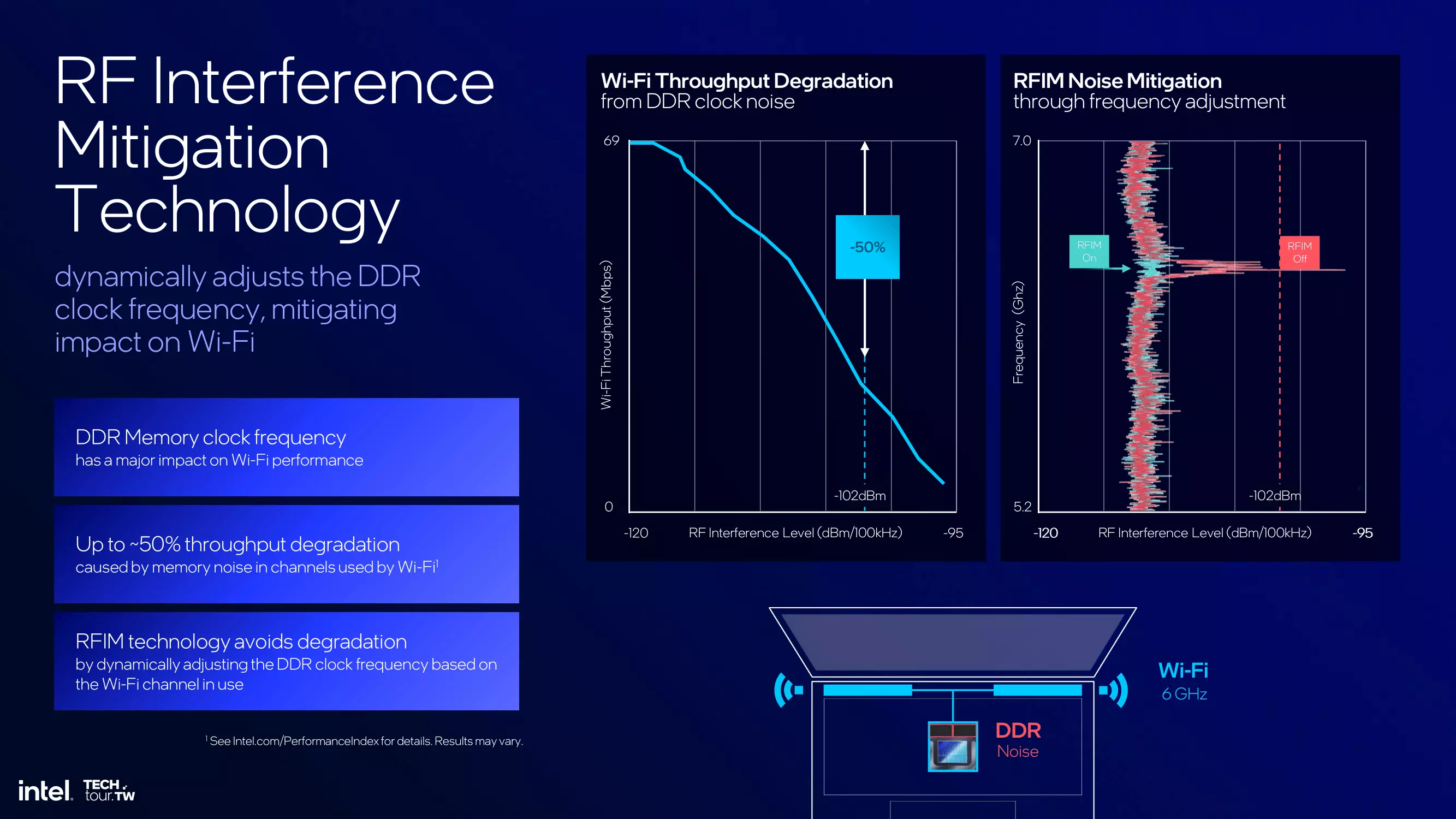
O nouă caracteristică utilă este tehnologia RF Interference Mitigation Technology, care ajută la creșterea stabilității semnalelor Wi-Fi prin ajustarea automată a vitezei de ceas a memoriei DDR pentru a evita interferențele cu semnalele Wi-Fi. Această inovație poate preveni până la 50% din degradarea lățimii de bandă din cauza zgomotului din memorie, ceea ce înseamnă că performanța wireless generală va fi mai bună și stabilitatea va fi îmbunătățită.
Este prezent și controlerul Thunderbolt 4, care poate folosi până la 3 porturi, cu o lățime de bandă totală de 40 Gbps. Placa include și controllere USB 3.2 de 5 Gbps și 10 Gbps și porturi USB 2.0, dar fiind vorba de notebook-uri subțiri și ușoare, nu multe dintre acestea vor fi disponibile.
Această secțiune include și controlerul PCI Express, care are în total opt benzi, dintre care patru sunt construite în jurul standardului 4.0, iar celelalte patru pe 5.0. De ce atât de puține benzi PCIe? Unitățile SoC Lunar Lake sunt destinate în mod special notebook-urilor subțiri și ușoare, unde spațiul este foarte limitat, și prin urmare, dispozitivele bazate pe PCIe nu prea au ce să servească, deoarece un dGPU iese din discuție. Cele patru benzi 4.0 pot fi folosite pentru nevoile generale ale platformei, în timp ce cele patru benzi 5.0 pot fi folosite pentru carduri SSD rapide.
Dacă aveți nevoie de o placă video, o puteți conecta la sistem prin intermediul portului Thunderbolt 4, folosind o carcasă externă pentru plăci video, sau puteți folosi o placă video externă de buzunar. Noile procesoare vin cu suport Thunderbolt Share anunțat anterior, care poate îmbunătăți considerabil colaborarea online, dar oferă și noi posibilități pentru utilizatorul obișnuit.
Data apariției în magazine
În prezent, echipa Intel plănuiește să debuteze procesoarele mobile Lunar Lake undeva în al treilea trimestru al acestui an, dar încă nu a fost dezvăluită data exactă.
