Nvidia și Amazon Web Services (AWS) au încheiat un parteneriat strategic pentru ca diferitele produse hardware ale Nvidia, special concepute pentru centrele de date, să fie disponibile pe AWS, împreună cu software-ul specializat al Nvidia. Părțile colaborează la mai multe proiecte de anvergură, dintre care cel mai mare este probabil Ceiba.
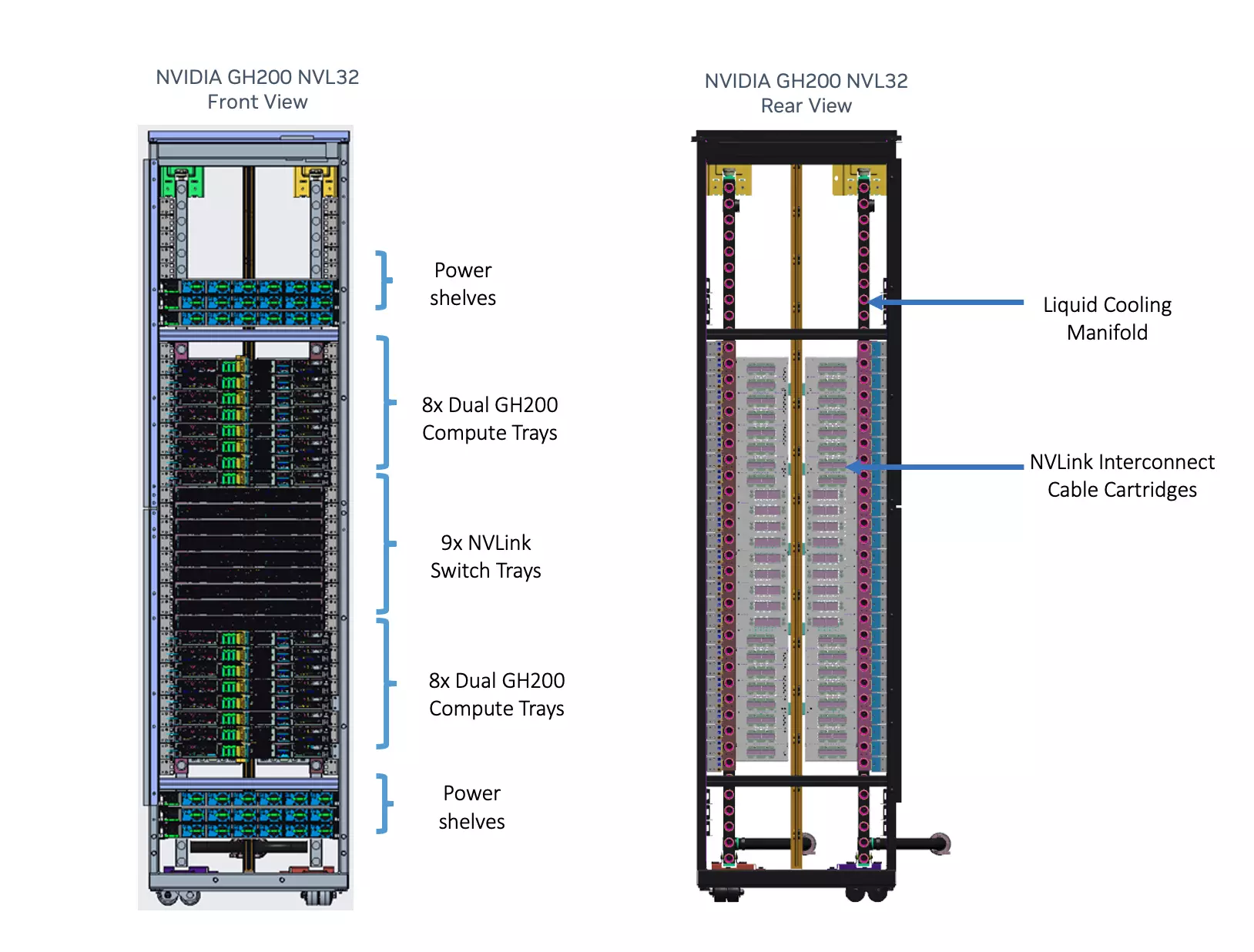
În cadrul proiectului Ceiba, AWS și Nvidia vor construi un cluster de supercomputere foarte impresionant dedicat sarcinilor de inteligență artificială, care se așteaptă să fie cel mai rapid de acest tip și care va fi disponibil exclusiv pentru Nvidia. Promițând să fie un campion în segmentul clusterelor de supercalculatoare AI accelerate de GPU, se așteaptă ca Project Ceiba să ofere o performanță maximă de calcul de 65 "AI ExaFLOP/s", iar rolul său principal va fi acela de a sprijini activitatea de cercetare și dezvoltare a Nvidia în domeniul AI generativ. Clusterul de supercomputere dedicat va fi alcătuit dintr-un total de 16.384 de superchipuri Nvidia GH200, ale căror elemente de bază vor fi sistemele GH200 NVL32, fiecare cu 32 de GPU GH200 și 19,5 TB de capacitate de memorie unificată.

O componentă importantă a colaborării va fi Nvidia DGX Cloud, care va fi disponibil în cadrul AWS. Aceasta este o platformă de instruire în domeniul inteligenței artificiale disponibilă ca serviciu, și va fi prima mașină virtuală disponibilă în comerț care va utiliza sistemul GH200 NVL32, cu cei 19,5 TB de memorie unificată.
Această platformă este atractivă pentru dezvoltatori nu numai datorită performanțelor sale de calcul ridicate, ci și pentru că oferă cea mai mare amprentă de memorie unificată într-o singură mașină virtuală. Platforma are potențialul de a accelera în mod semnificativ instruirea modelelor avansate de inteligență artificială generativă și a modelelor lingvistice de mari dimensiuni - va putea gestiona rețele neuronale cu până la 1 trilion de parametri.

AWS ar putea fi practic prima companie care oferă un cluster de supercalculatoare AI bazat pe cloud, alimentat de supercipurile Nvidia GH200 Grace Hopper Superchip. Configurația unică va pune la dispoziție un total de 32 de Grace Hopper Superchip-uri Grace Hopper pentru fiecare mașină virtuală, cu conectivitate bazată pe NVLink între ele. Sistemul poate include până la mii de GH200 Superchips conectate prin rețeaua EFA a Amazon.
O altă piatră de temelie a colaborării este faptul că mașinile virtuale Amazon EC2 pot fi acum susținute de GPU H200 Tensor Core, echipate cu 141 GB de memorie HBM3e la bord, deschizând noi posibilități pentru utilizatorii din spațiul de lucru al pieței AI și HPC. De asemenea, sunt disponibile și mașinile virtuale G6 și G6e, care utilizează acum acceleratoare Nvidia L4 și, respectiv Nvidia L40S. Pe lângă reglarea fină a AI, aceste acceleratoare pot ajuta, în fluxurile de lucru 3D și pot profita de Nvidia Omniverse pentru a crea aplicații 3D cu suport AI.

Pe lângă hardware, software-ul va juca un rol important în cadrul colaborării, permițând accelerarea semnificativă a sarcinilor care variază de la AI generativă la modele lingvistice mari (LLM), susținute de cadrul NeMo LLM și NeMo Retriever, care pot fi utilizate pentru a construi chatbots și instrumente de rezumat. BioNeMo va fi oferit, dar va fi utilizat în industria farmaceutică pentru a contribui la accelerarea cercetării privind diverse substanțe active.
