AMD a lansat două produse foarte importante la evenimentul Advancing AI, unde a fost prezentată și seria RYZEN 8040, unități APU mobile cu performanțe AI mai mari. Cele două produse importante sunt cei doi membrii ale seriei Instinct MI300, și anume acceleratorul bazat pe GPU de tip MI300X și unitatea APU de tip MI300A, care este prima unitate APU din segmentul centrelor de date.
Baza
Cei doi membri ai seriei MI300 se bazează în egală măsură pe patru chipset-uri I/O cu technologie de 6 nm, pe care sunt plasate diferite cantități și tipuri de componente. Cele patru cipuri I/O au un total de 256 MB de Infinity Cache, un total de 4x32 controlere de memorie HBM3 care gestionează canale de memorie pe 16 biți și un total de 128 de controlere PCIe care oferă benzi PCI Express 5.0. Acesta din urmă are patru benzi x16 dedicate pentru controlerul Infinity Fabric.

Plăcile I/O vor fi plăci XCD de 5 nm și/sau CCD de 5 nm, primele cu procesoare bazate pe CDNA3, iar cele din urmă cu nuclee de procesare bazate pe ZEN 4. În funcție de model, fie două XCD, fie trei CCD pot fi plasate deasupra unei plăci I/O. Placa XCD are un total de 38 de UC active din 40 de UC, în timp ce placa CCD are 8 nuclee de procesor bazate pe ZEN 4.
Acceleratorul bazat pe GPU, MI300X

Arhitectura acceleratorului bazat pe GPU MI300X este astfel concepută încât un total de opt plăci XCD bazate pe CDNA 3 sunt plasate deasupra celor patru plăci I/O menționate mai sus, rezultând un total de 304 blocuri CU active. În plus, există opt cipuri de memorie de tip 12hi, adică un total de 12 cipuri de memorie HBM 3 per chipset, oferind o capacitate totală de 192 GB la o lățime de bandă de memorie de 5,3 TB/s.
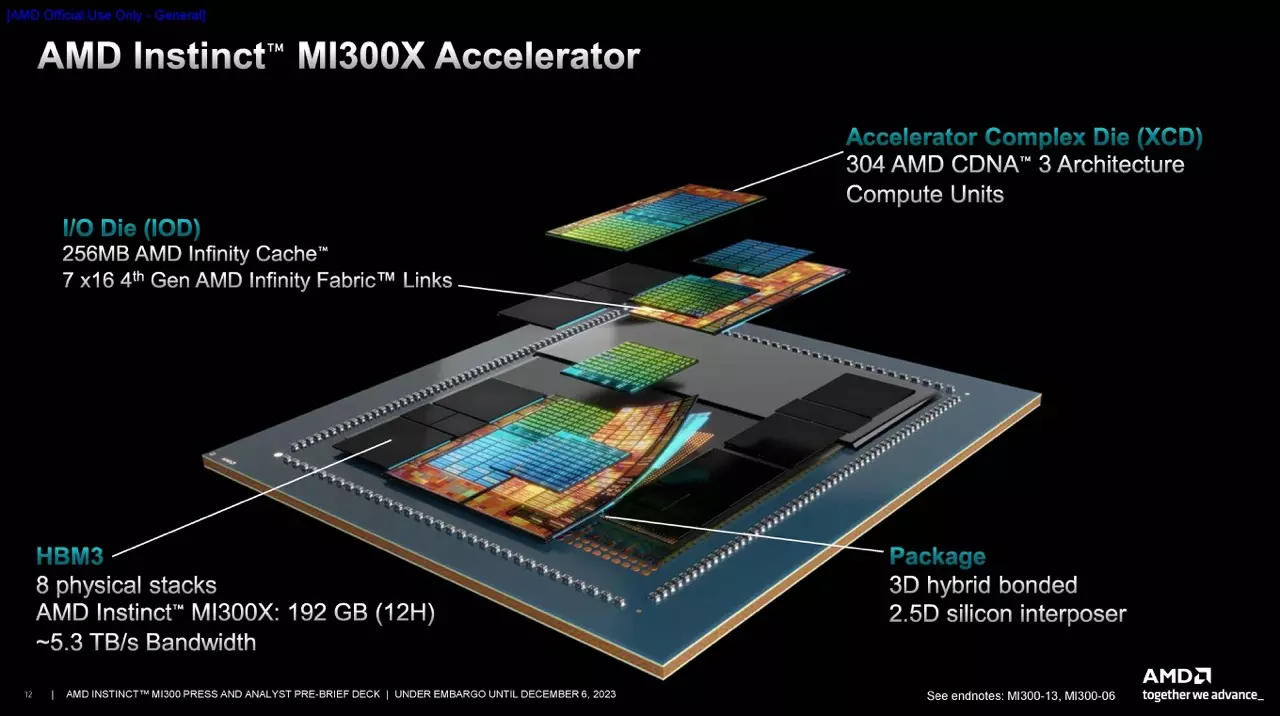
MI300X este o placă de accelerare cu un cadru TDP de 750 W, din care un total de opt pot funcționa împreună în cadrul platformei AMD MI300X. O interconectare Infinity Fabric cu o lățime de bandă de date de 896 GB/s conectează fiecare GPU, iar performanța de calcul combinată a sistemului poate ajunge la 10,4 PetaFLOP/s în modul de calcul BF16/FP16. Sistemul complet dispune de 1,5 TB de memorie HBM3 la bord.
Primul APU pentru centrele de date dispunând atât de nuclee CPU, cât și de nuclee GPU, MI300A. Primul APU pentru centre de date
MI300A este un nou-venit mai interesant, care combină cipurile GPU CDNA 3 și cipurile CCD bazate pe ZEN4, făcându-l disponibil ca APU pentru centrele de date. Noul produs este similar soluțiilor Nvidia din seria Grace Hopper SuperChip, dar cu nuclee de procesor x86 în loc de ARM. Acesta urmează același principiu în ceea ce privește elementele fundamentale, dar cu nuclee de procesor bazate pe ZEN4. În total sunt incluse trei dintre acestea, fiecare cu 8 nuclee, deci un maxim teoretic de 24 de nuclee.

Deoarece plăcile CDD ocupă spațiu de pe plăcile XCD, pot fi utilizate doar 6 dintre acestea în loc de 8, rezultând 228 de rețele de UC. Acest upgrade are mai puțină memorie HBM3 decât MI300X: "doar" 128 GB în loc de 192 GB, dar lățimea de bandă a memoriei rămâne aceeași, de 5,3 TB/s. Potrivit AMD, această reducere a capacității nu este necesară din cauza generării de căldură și a consumului de energie, ci pentru că produsul este optimizat pentru fluxurile de lucru HPC și AI din segmentul țintă. Deși capacitatea de memorie a fost redusă, există totuși o capacitate de memorie și o lățime de bandă de 1,6 ori mai mare decât cea a GPU-ului Nvidia H100 SXM, ceea ce nu sună rău pentru un API.

Unitatea APU MI300A încapsulată în SH5 are un cadru TDP implicit de 360W, dar acesta poate fi configurat până la 760W. AMD folosește alocarea dinamică a puterii pentru chipseturile CPU și GPU, ceea ce oferă mai multe cadre TDP pentru unul sau altul în funcție de volumul de lucru curent. Capsula SH5 folosește același soclu LGA6096 ca și soluția SP5 din seria EPYC, dar nu există suprapunere între cele două, ele diferă prin distribuția pinilor.
Performanța conform producător
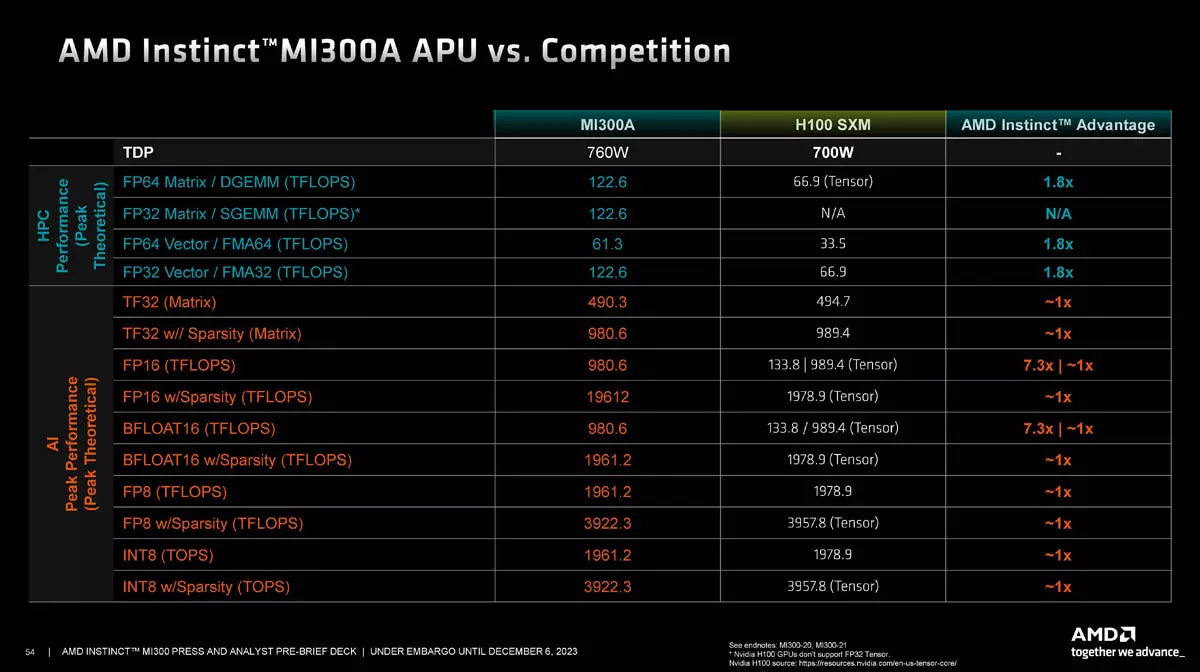
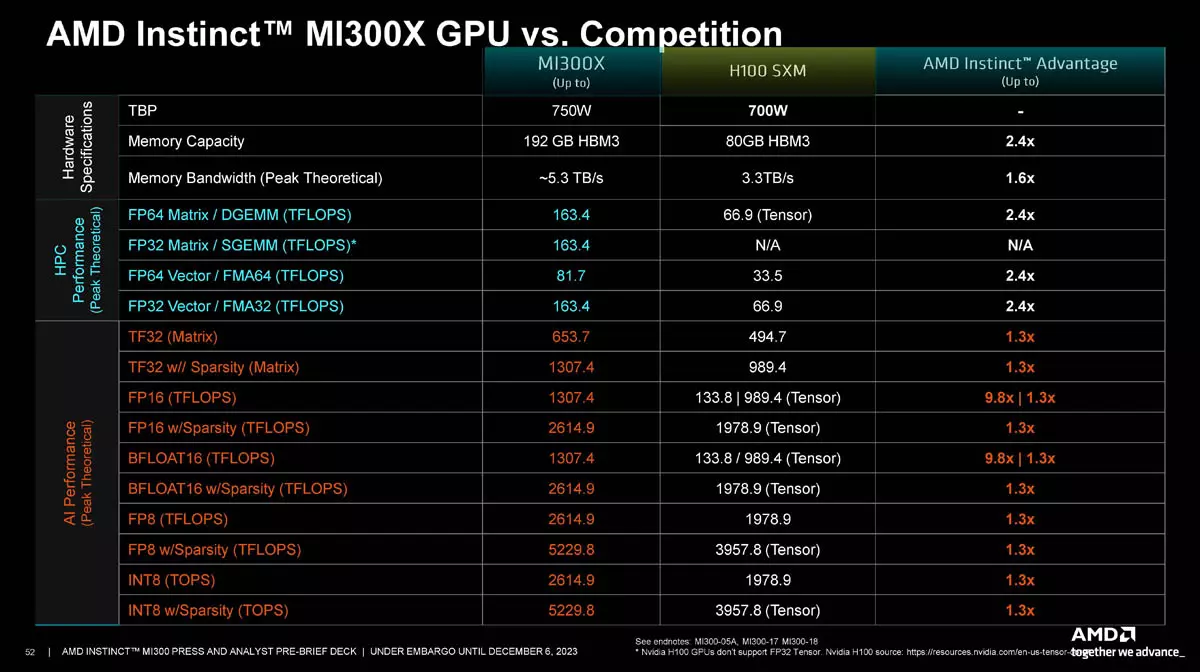
Platforma de acceleratoare MI300X a fost comparată cu platforma H100 HGX de la Nvidia, deoarece ambele sunt formate din opt - opt acceleratoare și vizează aceleași segmente de piață. În ceea ce privește performanța brută de calcul, AMD susține că platforma MI300X este de 2,4 ori mai bună decât soluția Nvidia pentru operațiile FP32 și FP64, în timp ce platforma MI300X poate oferi un avantaj de până la 1,3 ori mai mare pentru sarcinile INT8, FP8, BF16, FP16 și TF32 care se potrivesc cu formele de încărcare AI.

Potrivit AMD, noua platformă oferă o capacitate de memorie de 2,4 ori mai mare, ceea ce este foarte bine, deoarece capacitatea suplimentară de memorie permite sistemului să gestioneze o rețea neuronală de două ori mai mare: 70 de miliarde de modele pot fi antrenate pe platformă și 290 de miliarde de parametri pot fi gestionați, dublu cât Nvidia H100 HGX poate oferi. În ceea ce privește performanța, cele două platforme s-au comportat în mod similar în cadrul unei sarcini de antrenament MPT de 30 de miliarde de parametri, ceea ce este cu siguranță o veste bună pentru piață, deoarece înseamnă că, într-un mediu în care GPU-urile Nvidia sunt rare, ar putea merita să se apeleze la produsele AMD.

MI300A, sau acceleratorul de tip APU, este de 4 ori mai rapid decât H100 în testele interne ale AMD în cadrul testului OpenFoam HPC engine, ceea ce sună foarte bine, dar comparația este puțin cam dubioasă: se măsoară aspecte complet diferite. Acest test beneficiază foarte mult de calculul bazat pe CPU și GPU, iar avantajele spațiului de memorie partajat, plus natura sarcinii îi conferă un avantaj noului venit de la AMD.
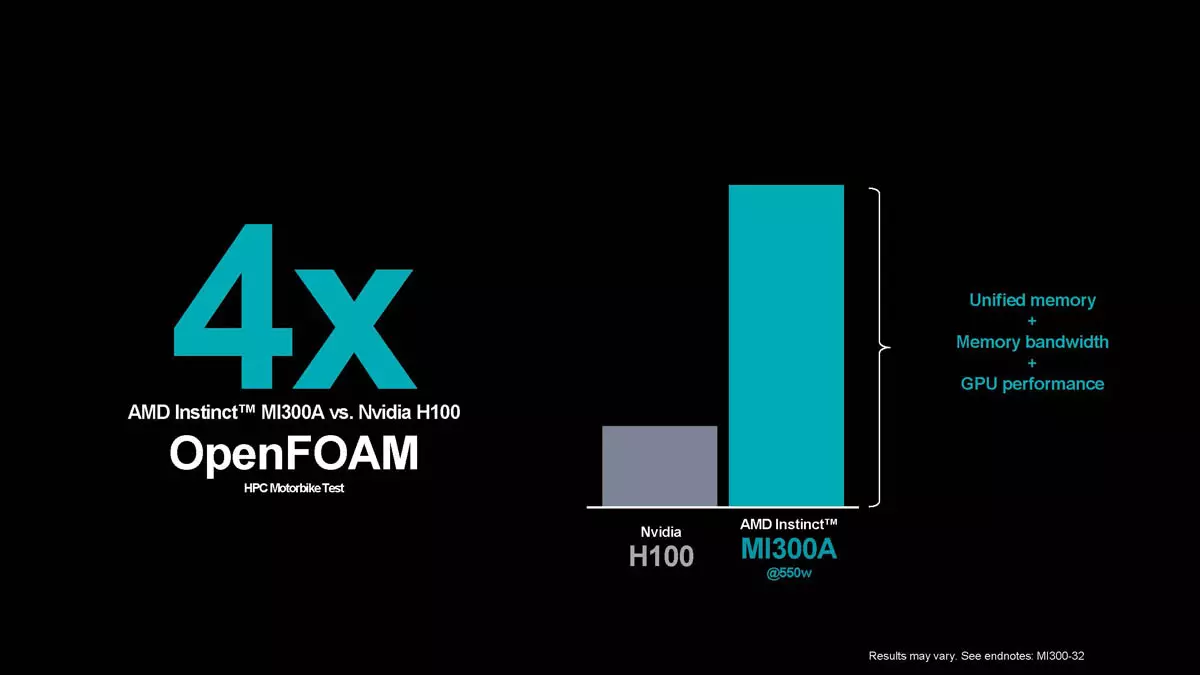
O imagine mult mai precisă ar fi să comparăm performanțele SuperChip-ului Grace Hopper GH200 cu cele ale MI300A, deoarece șansele ar fi mai egale, întrucât ambele produse combină nuclee CPU și GPU. Experții AMD nu au reușit să efectueze un astfel de test și nici nu s-a putut găsi rezultatele testului GH200 OpenFoam. Să sperăm că vor adăuga această comparație mai târziu.
În cele din urmă, iată rezultatele de comparație a performanțelor brute, care pot fi găsite în galeria de mai jos.
Seria Instinct MI300 pare destul de competitivă

Aceasta este o veste foarte bună pentru AMD, deoarece noile produse ar putea reduce într-o oarecare măsură dominația Nvidia pe piața AI și HPC, dacă industria are încredere în ele pe scară largă. Având în vedere lipsa de disponibilitate a GPU-urilor Nvidia, este posibil ca seria de acceleratoare MI300 să fie preluată mai repede și cu mai mult avânt decât în mod normal, ceea ce înseamnă că cota de piață a AMD ar putea crește rapid, dacă totul decurge în mod optim. Producția în serie a acceleratoarelor din seria MI300 este deja în plină desfășurare, iar produsele sunt livrate partenerilor.

{kind=link}